27. March 2025




The emergence of Artificial Intelligence has led many organizations to collect vast amounts of video for model training and analytics. In fields such as automotive, manufacturing, and retail, maintaining compliance with regulations and privacy laws (including GDPR) is critical when handling this sensitive data. While cloud platforms may already be part of your workflow, there are valid reasons to manage anonymization in-house. Here, we introduce two on-premises solutions: a scalable deployment on Kubernetes in AWS and a single-machine setup using Docker Compose.
Anonymizing in a Scalable Fashion on Kubernetes
The first brighter Redact on-premise option uses a Kubernetes cluster on AWS within private subnets of a dedicated VPC, managed via Terraform. This privacy-first architecture provides a solid security posture and simultaneously significant throughput for large-scale anonymization.
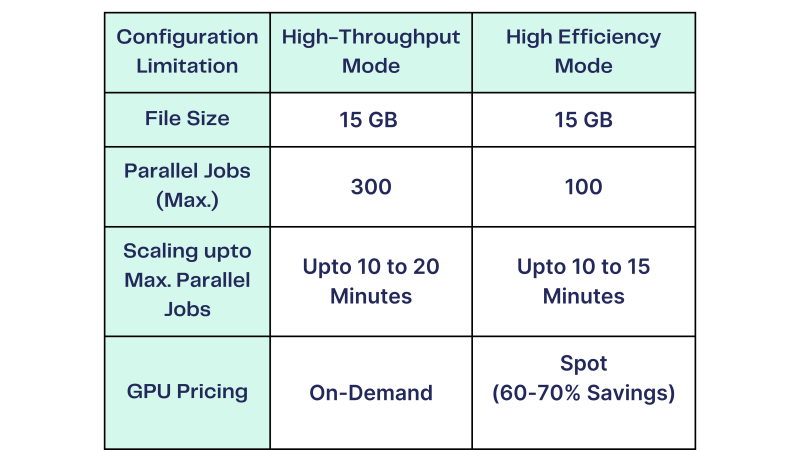
We offer two modes suited to different throughput needs and budgets. A high-efficiency mode can handle up to one hundred 15 GB videos in parallel, offering approximately 500 frames per second on up to 150 machines. This approach makes use of spot instances for cost-effectiveness. Meanwhile, a high-throughput mode processes up to three hundred 15 GB videos in parallel at thousands of per second on up to 400 machines, relying on on-demand instances for maximum stability.
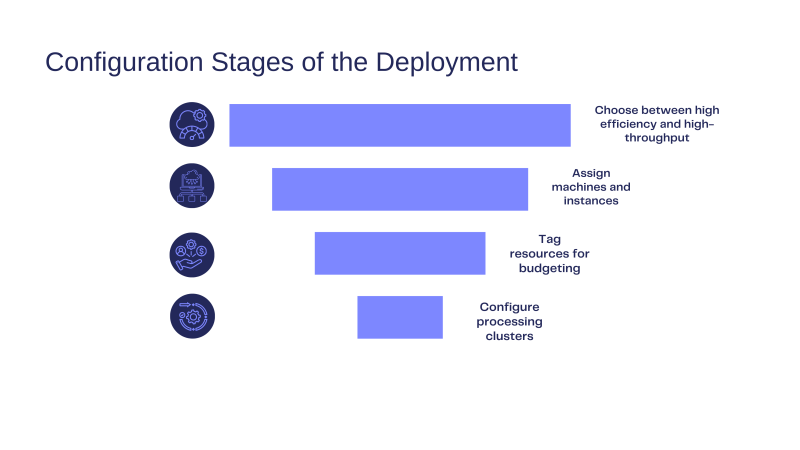
Both deployment modes come with an observability stack built on Loki, Prometheus, Thanos, and Grafana, so you can monitor resource usage, performance, and overall workflow health. For cost tracking, we tag all created resources through our IaC-first approach.
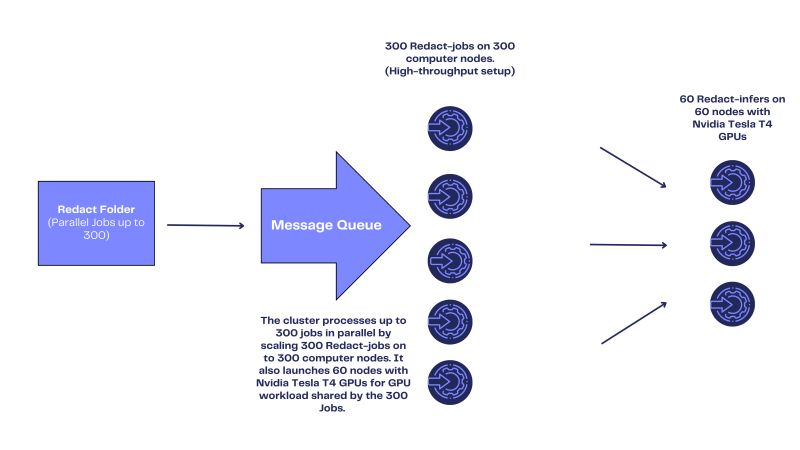
Our cloud engineers will support you in the process of creating one cluster or multiple clusters. The deployment will be tailored to your throughput and security needs. Future releases and updates are constantly shared with our customers. After the initial setup is completed, our experts will introduce you to sending jobs to our cluster REST API and using our in-house redact-client CLI to handle single files or entire folders, allowing processing multiple files in parallel.
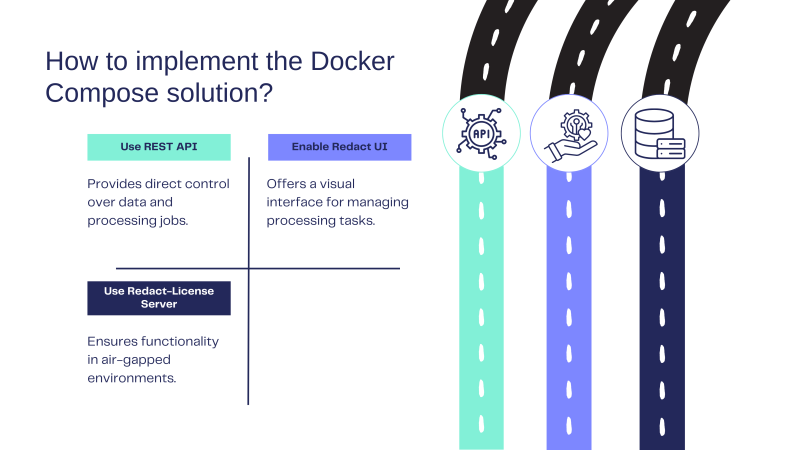
Anonymizing on a Single Machine with Docker Compose

If you are looking for a simple solution to get started or want to operate in an air-gapped environment, our Docker Compose solution runs on a single server equipped with one or multiple NVIDIA GPUs. Supported and speed-optimized options include T4, A100, 2080 Ti, and A10. This setup deploys the entire anonymization pipeline (pre-processing, deep-learning inference, and post-processing) behind a REST API, giving you direct control over incoming data. You can also enable a visual frontend (redact UI) to manage processing jobs if desired. For those environments without internet access, our dedicated Redact-License-Server ensures everything continues to function. The redact-client CLI and Python package can run single files or full directories for seamless integration into your pipelines.
Choosing between these two on-premise strategies depends on the volume of your data, as well as the available budget for meeting your privacy compliance. If you expect to process hundreds of hours of video daily and need elastic scalability, the Kubernetes cluster on AWS may be your best option. If you prefer a simpler approach or work in a secure, isolated setting, Docker Compose on a single machine offers a powerful yet contained solution.

To learn more about sizing, licensing, and cost, we invite you to reach out to our sales team at sales@brighter.ai. We will help you select and tailor the right anonymization architecture for your specific needs, ensuring you protect sensitive information without compromising on performance.


